

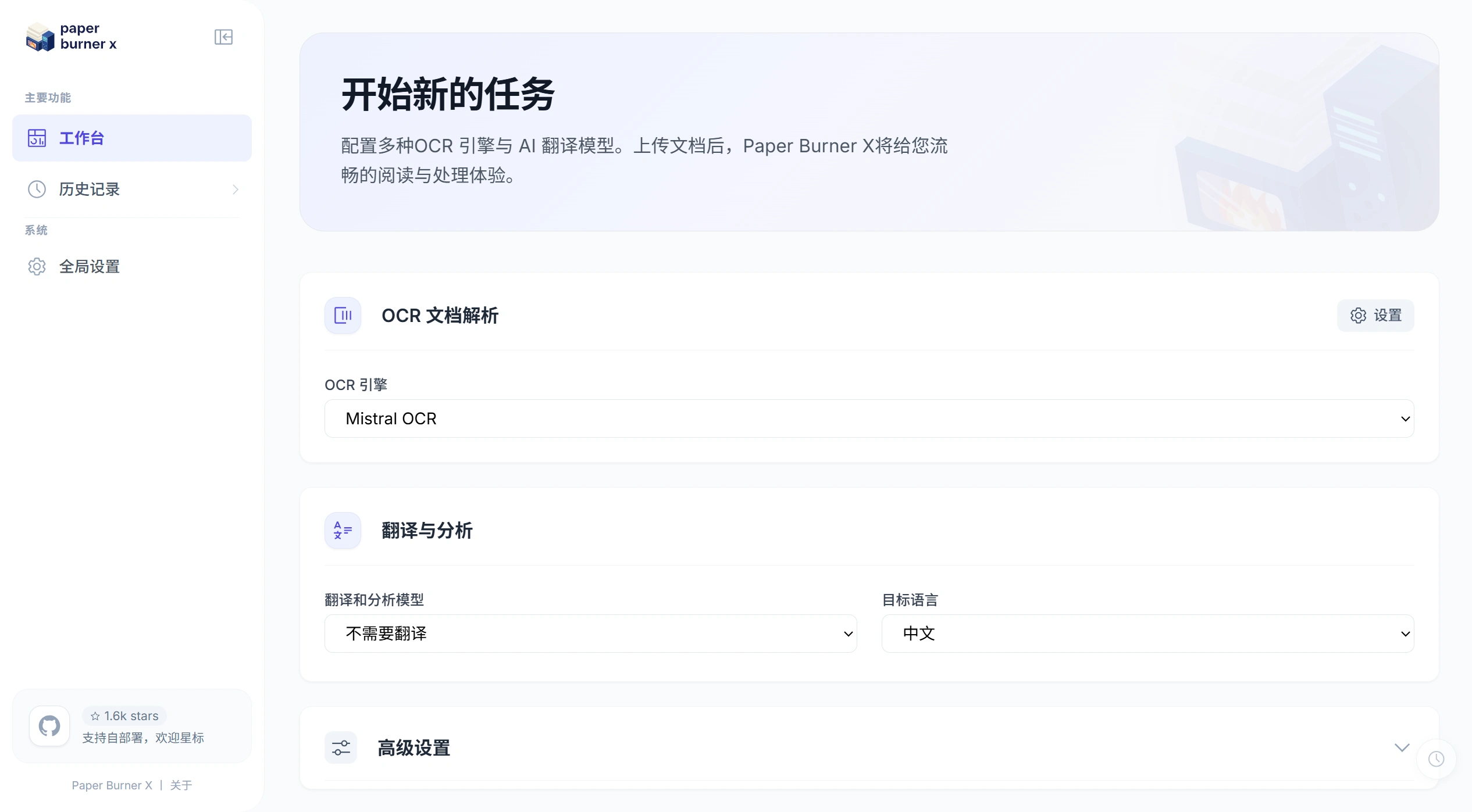
🎯 Paper Burner X 介绍
Paper Burner X 是一个开源的、浏览器里即开即用的 AI 工具,主要用来识别、翻译、阅读和分析文献。它的目标是帮你搞定大量 PDF、复杂公式和跨语言阅读这些麻烦事。如果你是需要精细、长文本阅读的研究人员或者深度学习者,它会比较适合你。它把文档处理、翻译和分析这些流程都整合到了一起,用起来比较顺畅。
✨ 主要功能特性
一体化文档处理引擎
多格式支持:PDF、DOCX、PPTX、EPUB、Markdown、HTML、TXT、YAML 等格式都可以导入导出
智能导入:支持本地上传,也能从 GitHub 仓库或任意链接直接导入
并发 OCR:支持 MinerU、Doc2X 等 OCR 引擎,扫描版 PDF 也能处理
术语库系统:支持几万条术语的快速匹配,翻译风格保持一致
极速并发翻译
多文件并发处理:一次传多个文件,自动排队处理
高速翻译:长篇论文几十秒就能翻完
格式保留:公式、图表、表格、引用格式都能原样保留
提示词池机制:智能管理提示词,保证翻译质量
前端 Agent 驱动的智能分析
这是 Paper Burner X 比较有特色的功能:
Agentic RAG 系统:在前端实现了一个长文本 Agent,让 AI 能看到整篇文章的结构
自主决策工具:AI 可以自己调用 grep 做精确匹配、向量搜索、内容抓取等工具,进行多步推理
结构化提取:内置“文献矩阵”工具,把非结构化的论文内容转成结构化数据
深度阅读体验优化
段落级对照阅读:原文和译文智能对齐,支持分块对比
目录导航:快速浏览文档结构
公式渲染:专门优化了复杂 LaTeX 公式的显示
标注与高亮:支持字级高亮和多种颜色标注
思维导图生成:自动生成文档的思维导图
🔧 技术架构与部署
部署方式
| 方式 | 特点 | 适用场景 |
|---|---|---|
| 纯前端部署 | 数据存储在浏览器本地(IndexedDB),无需服务器,隐私保护最佳 | 个人用户快速体验 |
| Vercel 部署 | 5 分钟内完成免费静态部署 | 个人定制化使用 |
| Docker 部署 | 包含完整前后端服务(开发中) | 企业内网或私有环境 |
| OCR Server | 可自托管的 OCR 服务 | 需要离线 OCR 能力 |
隐私与安全
纯前端模式:所有数据在浏览器本地处理,不上传远程服务器
BYOK(Bring Your Own Key):用户自己接入 AI 模型的 API Key
多 Key 轮询:支持多个 API Key 轮着用,提高稳定性
🚀 适用场景
学术研究:快速处理大量外文文献,辅助文献综述和课题研究
深度学习:精细化的长文本阅读,高效学习和管理知识
企业文档处理:在受控网络环境里自托管部署,满足数据合规要求
跨语言信息处理:用术语库保证多语言信息传递的准确性
Paper Burner X 快速使用指南
在线版:https://paperburner.viwoplus.site/
数据存在浏览器本地,刷新不丢,清缓存会丢
或者用 Vercel 部署:Fork GitHub 仓库 → 导入 Vercel → 一键部署
3 步上手
配 Key
设置 → 填入 OpenAI/Claude API Key(支持多 Key 轮询)
传文件
支持 PDF/DOCX/PPTX/EPUB/Markdown/网页链接
扫描版 PDF 会自动走 OCR(支持 MinerU、Doc2X)
读 + 译
双栏对照:原文和译文段落对齐
术语库:专业术语自动统一
AI Agent:提问就能自动检索、提取文献矩阵
核心功能
⚡ 长篇论文秒翻(保留公式、图表)
🔍 前端 Agent 自主决策(grep 精准搜索 + 向量语义检索)
📝 高亮标注、思维导图、目录导航
🔒 纯前端处理,文件不出本地(BYOK 模式)
导出:翻译结果可以导出 PDF/Markdown/DOCX 等格式






























 论文工具
论文工具 文献管理
文献管理 中文文献
中文文献 英文文献
英文文献 选刊投稿
选刊投稿 专利检索
专利检索 学术检索
学术检索 学术社区
学术社区 AI+学习
AI+学习  英语学习
英语学习  考研考公
考研考公  出国留学
出国留学  资格考试
资格考试  学习平台
学习平台  宝藏网站
宝藏网站 