

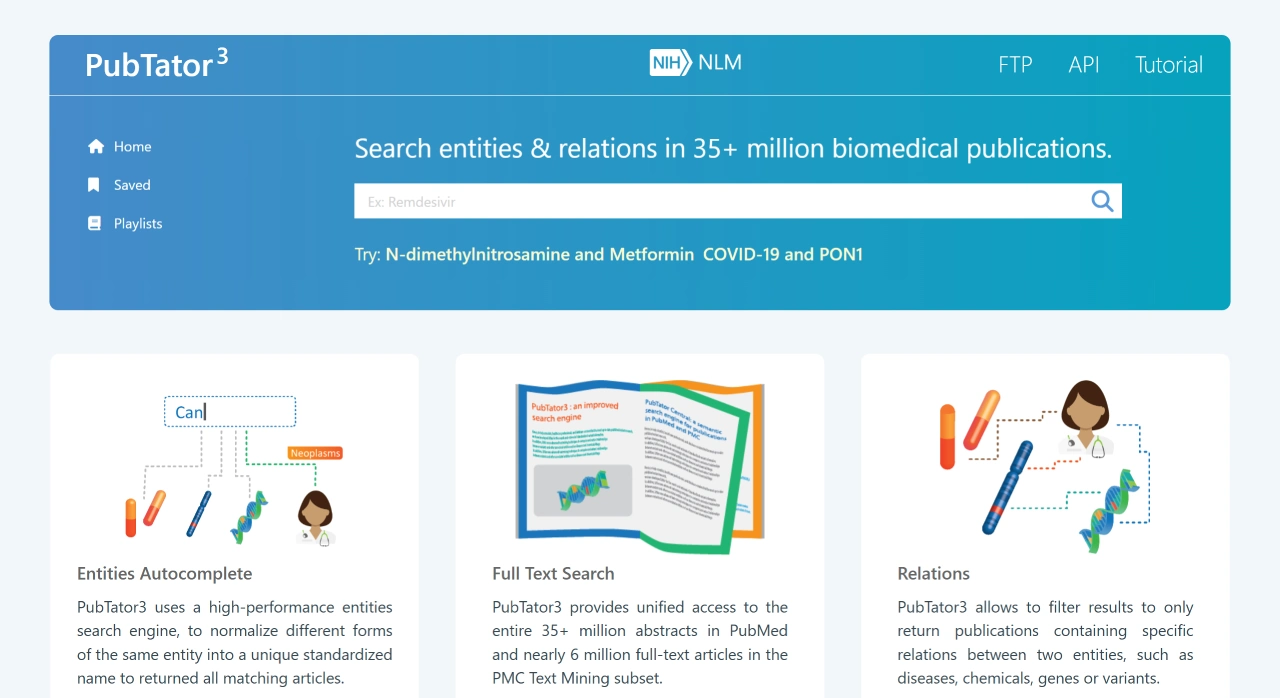
PubTator是个能自动识别并标注PubMed摘要和全文里的生物实体的在线工具,主要用在生物医学领域,能帮着整理文献里的生物信息,做文献综述和数据提取,支持大规模文本分析,也能用来开发新的文本挖掘和自然语言处理方法。
PubTator 3.0现在收录了超过16亿个实体标注和3300万条关系标注,覆盖了PMC开放获取部分的约3600万篇PubMed摘要和600万篇全文,每周都会更新。
PubTator主要功能特点
识别标注实体:能自动认出并标注多种生物相关内容,像基因、蛋白质、疾病、化学物质、物种和细胞系等。
数据整合:和PubMed数据库连着,能给PubMed里2900万篇摘要和PMC文本挖掘部分的300万篇全文做标注。
操作方便:网页界面简单好用,用户能自己选文章集合,还能看到每篇文章里标注的概念。
多种输出格式:标注数据能导出成XML、JSON和制表符分隔格式等,方便后续处理分析。
支持开发:提供API接口,能和其他工具连起来,方便开发人员二次开发。
智能搜索:PubTator 3.0用人工智能技术,支持语义和关系搜索,能查六种生物医学实体的标注,还能找出12种常见的实体关系。
PubTator能用来做什么
找文献:帮研究人员在海量的生物医学文献里,快速找到和特定生物概念相关的文献,还能直接定位到具体句子或段落。
发现知识:通过识别文献里的实体和它们之间的关系,给生物医学研究提供有用信息,加快科研发现。
辅助语言模型:和大型语言模型(比如ChatGPT)连起来用,能让模型的回答更准确,减少出错的可能。
PubTator怎么用
在线操作:通过PubTator网站直接查文献。
API调用:用API接口能搜关键词、实体和关系,还能导出标注数据。
批量下载:通过FTP站点能批量下载标注好的文章和摘要。
PubTator最开始是美国国立生物技术信息中心(NCBI)开发的,目的是给生物医学研究人员提供一个好用的文本挖掘工具。后来技术不断更新,功能和性能也变得更强大。






























 论文工具
论文工具 文献管理
文献管理 中文文献
中文文献 英文文献
英文文献 选刊投稿
选刊投稿 专利检索
专利检索 学术检索
学术检索 学术社区
学术社区 AI+学习
AI+学习  英语学习
英语学习  考研考公
考研考公  出国留学
出国留学  资格考试
资格考试  学习平台
学习平台  宝藏网站
宝藏网站 